两者关系
Transformer与ChatGPT模型的出现密切相关。事实上,Transformer自提出之后就被广泛应用并不断扩展。例如DeepMind公司就应用Transformer构建了蛋白质结构预测模型AlphaFold 2,现在Transformer也进入了计算机视觉领域,在许多复杂任务中正慢慢取代卷积神经网络。
可以说,Transformer已经成为深度学习和深度神经网络技术进步的最亮眼成果之一。
提到Transformer,大家肯定首先想到的就是“transform”这个词,也就是“转换”的意思。而顾名思义,Transformer也就是“转换器”的意思。为什么一个技术模型要叫“转换器”呢?其实,这也正是Transformer的核心,也就是它能实现的功能——从序列到序列。但这个从序列到序列,可不是简单地从一个词跳到另一个词,中间要经过很多道“工序”,才能实现想要的效果。
很多人肯定对“序列”这个词感到疑惑,实际上它是由英文单词“sequence”翻译过来的。序列,指的是文本数据、语音数据、视频数据等一系列具有连续关系的数据。不同于图片数据,不同图片之间往往不具有什么关系,文本、语音和视频这种数据具有连续关系。这些数据在这一时刻的内容,往往与前几个时刻的内容相关,同样也会影响着后续时刻的内容。
在机器学习中,有一类特殊的任务,专门用来处理将一个序列转换成另外一个序列这类问题。例如我们熟知的翻译任务,就是将一种语言的文字序列转换成另一种语言的文字序列。再例如机器人聊天任务,本质上也是将问题对应的文字序列转换成回答对应的文字序列。我们将这种问题称为序列到序列问题,也是Transformer的核心、深度学习最令人着迷的领域之一。
序列
序列到序列任务一般具有以下两个特点:
(1)输入输出序列都是不定长的。比如说机器翻译场景下,待翻译的句子和翻译结果的长度都是不确定的。
(2)输入输出序列中元素之间是具有顺序关系的。不同的顺序,得到的结果应该是不同的,比如“我不喜欢”和“喜欢我不”这两个短语表达了两种完全不一样的意思。
序列到序列模型一般是由编码器(encoder)和解码器(decoder)组成的。
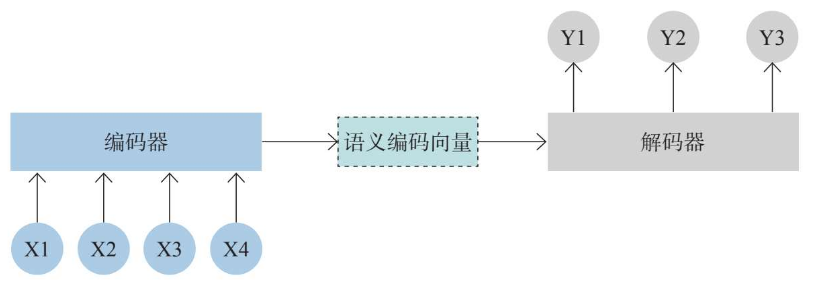
Transformer
Transformer模型在普通的编码器—解码器结构基础上做了升级,它的编码端是由多个编码器串联构成的,而解码端同样由多个解码器构成。它同时也在输入编码和自注意力方面做了优化,例如采用多头注意力机制、引入位置编码机制等等,能够识别更复杂的语言情况,从而能够处理更为复杂的任务。
例如:“She bought a book and a pen.”(她买了书和笔。)这句话中的两个“a”修饰的是 什么?是“book”还是“pen”?意思是“一本”还是“一支”?这对人类来说也是一个简单的问题, 但对模型来说却比较困难,如果只使用自注意力机制,可能会忽略两个“a”和它们后面名词之间的关系,而只关注“a”和其他单词之间的相关性。引入位置编码就能很好地解决这个问题。通过加入位置编码信息,每个单词都会被加上一个表示它在序列中位置的向量。
通过引入多头注意力机制、位置编码等方式,Transformer有了最大限度理解语义并输出相应回答的能力,这也为后续GPT模型这种大规模预训练模型的出现奠定了基础。
GPT系列模型
GPT属于典型的“预训练+微调”两阶段模型。一般的神经网络在进行训练时,先对网络中的参数进行随机初始化,再利用算法不断优化模型参数。而GPT的训练方式是,模型参数不再是随机初始化的,而是使用大量通用数据进行“预训练”,得到一套模型参数;
然后用这套参数对模型进行初始化,再利用少量特定领域的数据进行训练,这个过程即为“微调”。预训练属于迁移学习的一种。预训练语言模型把自然语言处理带入了一个新的阶段——通过大数据预训练加小数据微调,自然语言处理任务的解决无须再依赖大量的人工调参。
GPT系列的模型结构秉承了不断堆叠Transformer的思想,将Transformer作为特征抽取器, 使用超大的训练语料库、超多的模型参数以及超强的计算资源来进行训练,并通过不断提升训练语料的规模和质量,提升网络的参数数量,完成迭代更新。GPT模型的更新迭代也证明了,通过不断提升模型容量和语料规模,模型的能力是可以不断完善的。
GPT-3则是用“45TB(万亿字节)的训练数据,175B(1750亿个)参数的参数量”这样的数据量把模型规模做到了极致。这也使得GPT-3模型无须或者使用极少量的样本进行微调就能完成特定领域的自然语言处理任务,并且在很多数据集上直接超过了经过精心调整的微调模型的效果,这样在节省模型训练时间的同时,特定领域中需要大量标注语料的问题也迎刃而解。
ChatGPT是在GPT-3.5模型基础上的微调模型。在此基础上,ChatGPT采用了全新的训练方式——“从人类反馈中强化学习”。通过这种方式的训练,模型在语义理解方面展现出了前所未有的智能。
ChatGPT的训练分为三个步骤:
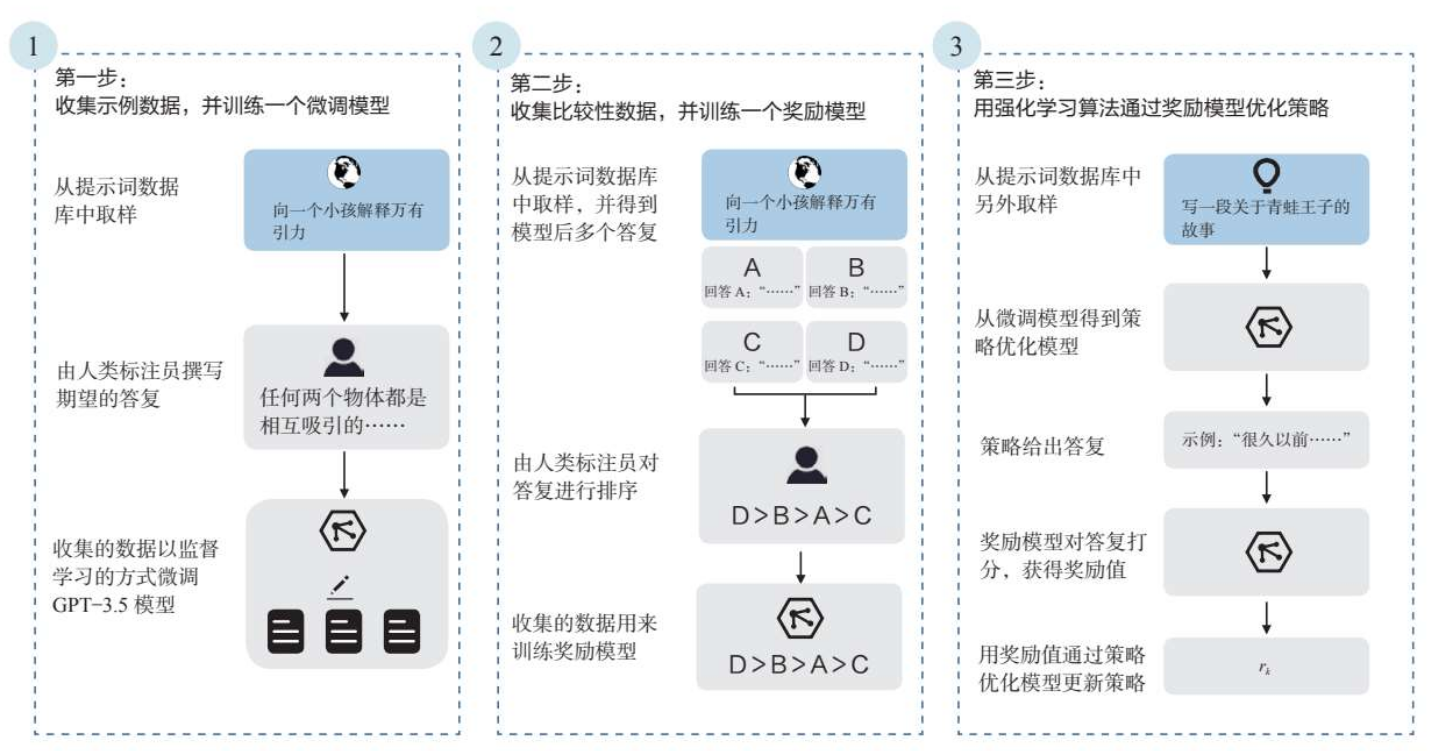
第一步,通过人工标注的方式生成微调模型。标注团队首先准备一定数量的提示词样本,一部分由标注团队自行准备,另一部分来自OpenAI现有的数据积累。然后,他们对这些样本进行了标注,其实就是人工对这些提示词输出了对应的答复,从而构成了“提示词—答复对”这样的数据集。最后用这些数据集来微调GPT-3.5,得到一个微调模型。
第二步,训练一个可以评价答复满意度的奖励模型。同样准备一个提示词样本集,让第一步得到的模型来对其进行答复。对于每个提示词,要求模型输出多个答复。标注团队需要做的工作,就是将每个提示词的答复进行排序,这其中隐含了人类对模型输出效果的预期,以此形成了新的标注数据集,最终用来训练奖励模型。通过这个奖励模型,可以对模型的答复进行打分,也就为模型的答复提供了评价标准。
第三步,利用第二步训练好的奖励模型,通过强化学习算法来优化答复策略。这里采用的是一种策略优化模型,它会根据正在采取的行动和收到的奖励不断调整当前策略。具体来说,首先准备一个提示词样本集,对其中的提示词进行答复,然后利用第二步训练好的奖励模型去对该答复进行打分,根据打分结果调整答复策略。在此过程中,人工已经不再参与,而是利用“AI训练AI”的方式进行策略的更新。最终重复这个过程多次之后,就能得到一个答复质量更好的策略。