Anything LLM 是一款轻量、开源、易部署的本地知识库工具,和 Ollama 搭配能完美实现「本地模型 + 私有化文档问答」,全程数据不联网,比 FastGPT/Dify 更轻量化。
核心优势
- 极简部署:无需复杂依赖,Docker / 本地脚本均可启动;
- 全本地化:模型(Ollama)+ 文档(Anything LLM)全在本地,隐私拉满;
- 适配性强:支持 PDF/Word/TXT/Markdown 等几乎所有文档格式;
- 灵活扩展:可自定义模型、嵌入向量、上下文长度,满足不同场景。
前置准备
已完成的基础
已安装 Ollama(参考之前的教程,能正常运行 qwen:7b-chat/glm4:7b 等中文模型);
已安装 Docker(推荐,一键部署 Anything LLM;无 Docker 也可本地运行);
硬件:至少 8GB 显存(跑 7B 模型)/ 16GB 内存(纯 CPU 运行)。
验证 Ollama 可用性
打开终端执行:
# 检查Ollama是否运行
ollama ps
# 测试模型响应(确保qwen:7b-chat已下载)
ollama run qwen:7b-chat "你好"
能正常返回结果说明 Ollama 没问题。
部署步骤
步骤 1:创建数据目录(持久化存储文档 / 配置)
# Windows(CMD)
mkdir C:\anything-llm-data
# Linux/macOS
mkdir -p ~/anything-llm-data
步骤 2:启动 Anything LLM 容器
docker run -d \
--name anything-llm \
--restart always \
-p 3001:3001 \
-v ~/anything-llm-data:/app/server/storage \
-e OLLAMA_BASE_URL=http://host.docker.internal:11434 \
mintplexlabs/anything-llm:latest
步骤 3:初始化配置
打开浏览器访问 http://localhost:3001,首次进入会引导配置;
设置管理员密码:创建账号密码(本地登录用,务必记住);
选择 LLM 提供商:选「Ollama」,自动填充地址(http://host.docker.internal:11434),点击「Test Connection」测试连接(显示 Success 即成功);
选择默认模型:下拉框选已下载的模型(如 qwen:7b-chat/glm4:7b);
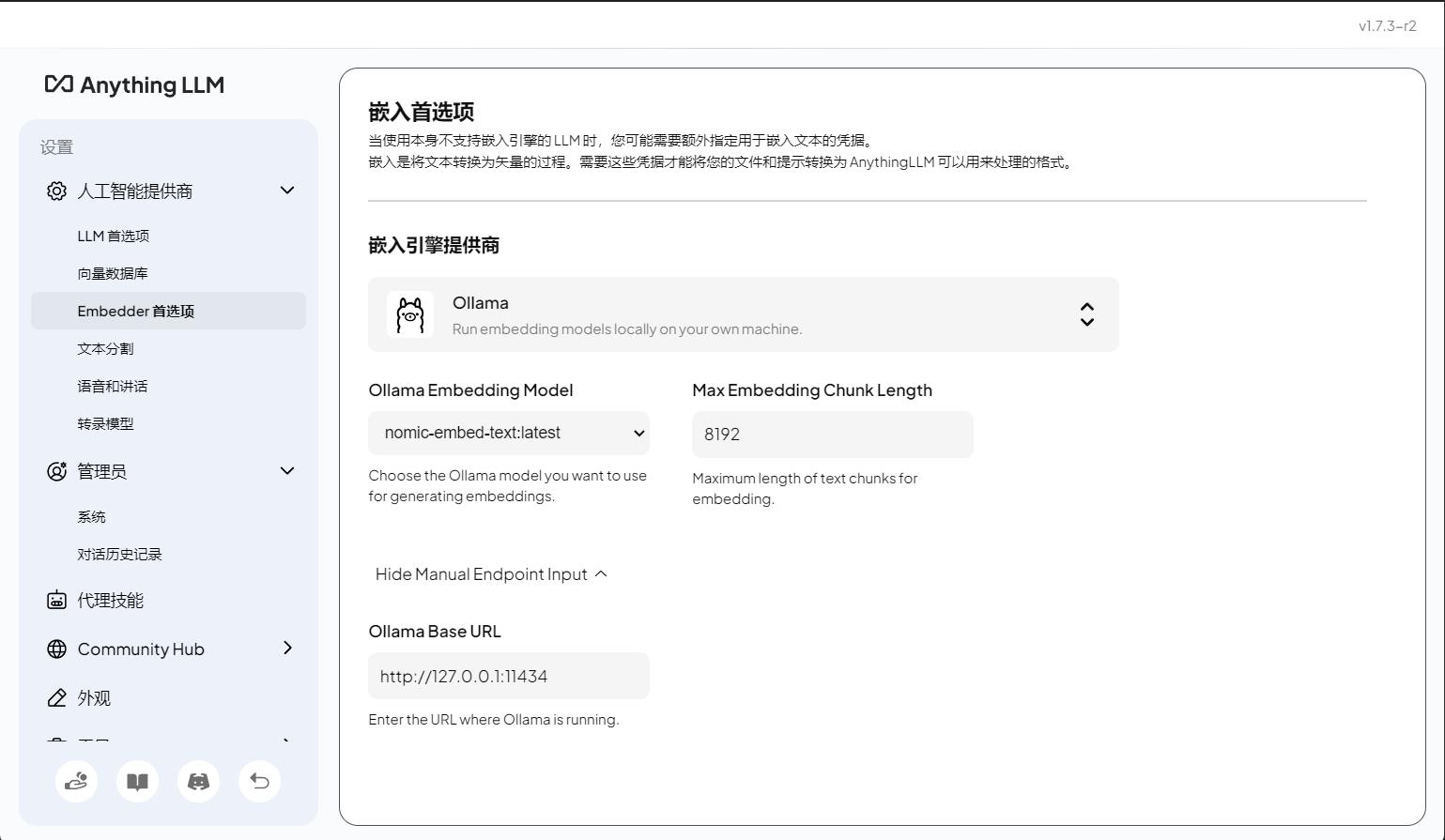
嵌入模型配置:推荐选「BAAI/bge-large-zh-v1.5」(中文嵌入效果最优,会自动下载);
完成配置,进入 Anything LLM 主界面。
核心使用流程
步骤 1:创建工作区(Workspaces)
点击左侧「Workspaces」→「Create Workspace」; 输入名称(如「公司知识库」「个人笔记」),选择默认模型 / 嵌入模型,点击创建。
步骤 2:上传文档
进入创建好的工作区,点击「Upload Files」; 选择要上传的文档(PDF/Word/TXT 等,支持批量上传); 点击「Process Files」,等待文档解析 + 嵌入(7B 模型处理 100 页 PDF 约 5-10 分钟)。
步骤 3:本地问答
文档处理完成后,在右侧聊天框输入问题(如「这份合同的付款条款是什么?」「总结这份技术文档的核心功能」); 模型会基于本地文档内容回答,全程不联网,数据仅保存在本地目录。
关键配置优化(提升问答效果)
模型参数调整
在工作区「Settings」→「Model Settings」:
Temperature:设为 0.1~0.3(越低越严谨,适合知识库问答;越高越有创造力);
Context Window:设为 4096~8192(匹配 Ollama 模型的上下文长度,qwen:7b-chat 默认支持 8192);
Top K:设为 40(控制召回的相关文档片段数量)。
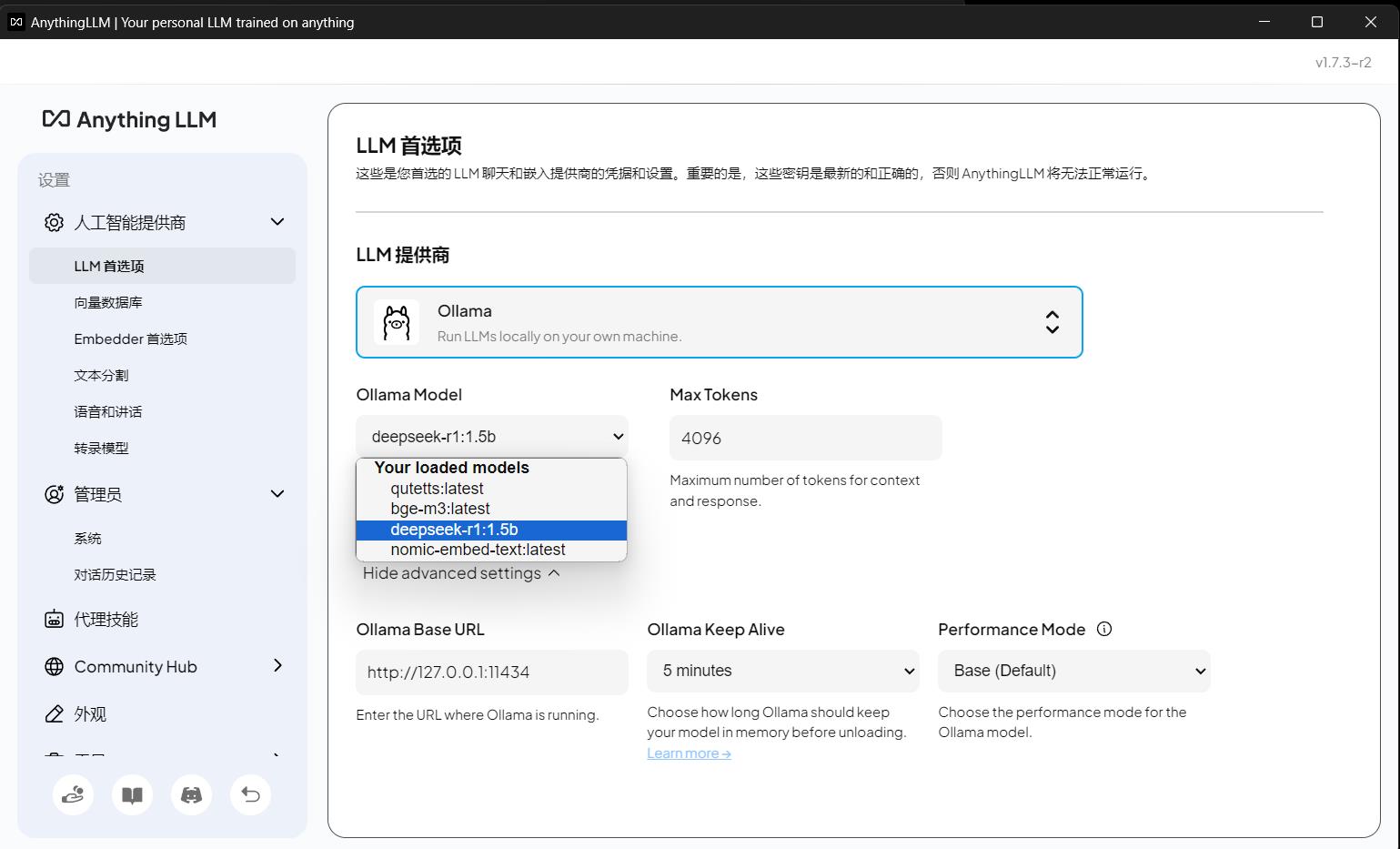
中文优化
嵌入模型必须选「BAAI/bge-large-zh-v1.5」(中文语义理解远超英文嵌入模型);
LLM 优先选国产模型:qwen:7b-chat(中文流畅)/glm4:7b(推理 / 编程强)。
文档预处理(提升解析效果)
PDF 若扫描件(图片版):先转成可复制的文本版(用 OCR 工具),否则 Anything LLM 无法解析; 长文档(500 页 +):拆分后分批上传,避免解析超时。