概念
Skills这个概念最早由 Anthropic 公司提出,作为其大模型 Claude 的一种能力扩展机制。
简单来说就是,一份改变AI Agent行为的文档,仅此而已。
它本意为技能的意思,加了复数s那么就是一份技能包咯。像是游戏里的技能小连招,在智能体工具里,可以自行创建Skill,也可以到社区里获取其他人分享的Skill。目前主流的智能体工具,基本上多接入了Skills,那么这个Skill由什么组成呢?
本质上就是一个叫SKILL.md的文本文件。Markdown格式,用自然语言写成。没有代码,没有编译,没有API调用。你用记事本就能创建一个Skill,其内容是一份提前写好的工作指南,告诉Agent在面对某一类任务时:遵循什么步骤、输出什么格式、注意哪些细节。
如何应用
比如我想让AI帮我写周报,你可以把周报的要求,固定格式,文字限制,去AI味儿等等,用Markdown格式写一下,也可以让AI帮你写一份,然后配置好去应用,比如,以下是让AI随便给一个范范的周报模板:
---
name: 智能工作周报自动生成
description: 通用工作周报生成技能
---
根据用户提供的零散工作内容、碎片记录、日常任务,自动结构化梳理、润色拔高、量化成果、总结问题、规划下周计划,输出一份职场正式、干净、通用的标准工作周报。
适用岗位:运营、行政、人事、技术、销售、产品、职能岗、实习生、通用职场
# 输出风格:简洁专业、务实不浮夸、职场正式、逻辑清晰
# Skill 触发规则(AI自动执行)
# 当用户出现以下任意指令,自动启用本 Skill:
- 帮我写周报 / 生成周报
- 整理一下本周工作
- 把我这些工作写成周报
- 输出本周工作总结+下周计划
- 任何隐含“周报、本周总结、工作汇总”需求
# Skill 工作逻辑(AI执行步骤)
1. 收集信息:读取用户给出的所有本周工作碎片、任务、事项、成果、问题
2. 分类梳理:自动区分:已完成工作、重点成果、问题与不足、下周计划
3. 职场润色:口语转书面、短句扩写、补充工作价值、弱化流水账
4. 量化优化:无数据则补价值描述,有数据优先突出数据成果
5. 结构化输出:固定标准周报模板,排版整洁、分段清晰
# 固定输出模板(强制格式)
# 所有周报统一按以下四段输出,不可乱改结构:
一、本周工作完成情况
逐条罗列本周核心工作、落地事项、执行内容,对每一项工作补充执行过程与落地价值,避免简单罗列。
二、本周工作成果与亮点
提炼本周重点产出、优化改进、效率提升、数据成果、推进突破,突出个人价值与工作贡献。
三、存在问题与反思
客观说明工作中的不足、卡点、待优化问题,不敷衍、不消极,同时写出对应反思原因。
四、下周工作计划
对应本周工作衔接,列出清晰、可落地、有优先级的下周工作安排,条理清晰、贴合岗位实际。
# Skill 写作规范(核心规则)
- 去流水账:禁止“做了XX、干了XX”简单口语,必须写清楚:做了什么+怎么做+达成什么效果
- 适度拔高:基于事实优化,不虚假夸大,合理体现工作价值
- 逻辑清晰:同类工作合并,零散事项归类,不杂乱
- 职场正式:用词专业、稳重、适合上交领导
- 适配不同岗位:自动根据用户工作内容适配岗位风格(技术偏落地、运营偏数据、职能偏统筹)
# 用户输入示例(适配训练)
# 用户:这周做了日常数据统计,整理了表格,对接了两个部门,处理一些临时工作,有点拖延,下周想把工作提前规划好。
AI自动优化后输出标准周报(自动润色、结构化、补全价值)
Skill 兜底机制
如果用户输入内容极少、内容零散:自动补全合理岗位常规工作,生成完整可用周报,不空白、不敷衍,保证直接上交可用。
然后将他配置到本地AI工具中,我这里暂时用的 Trae。
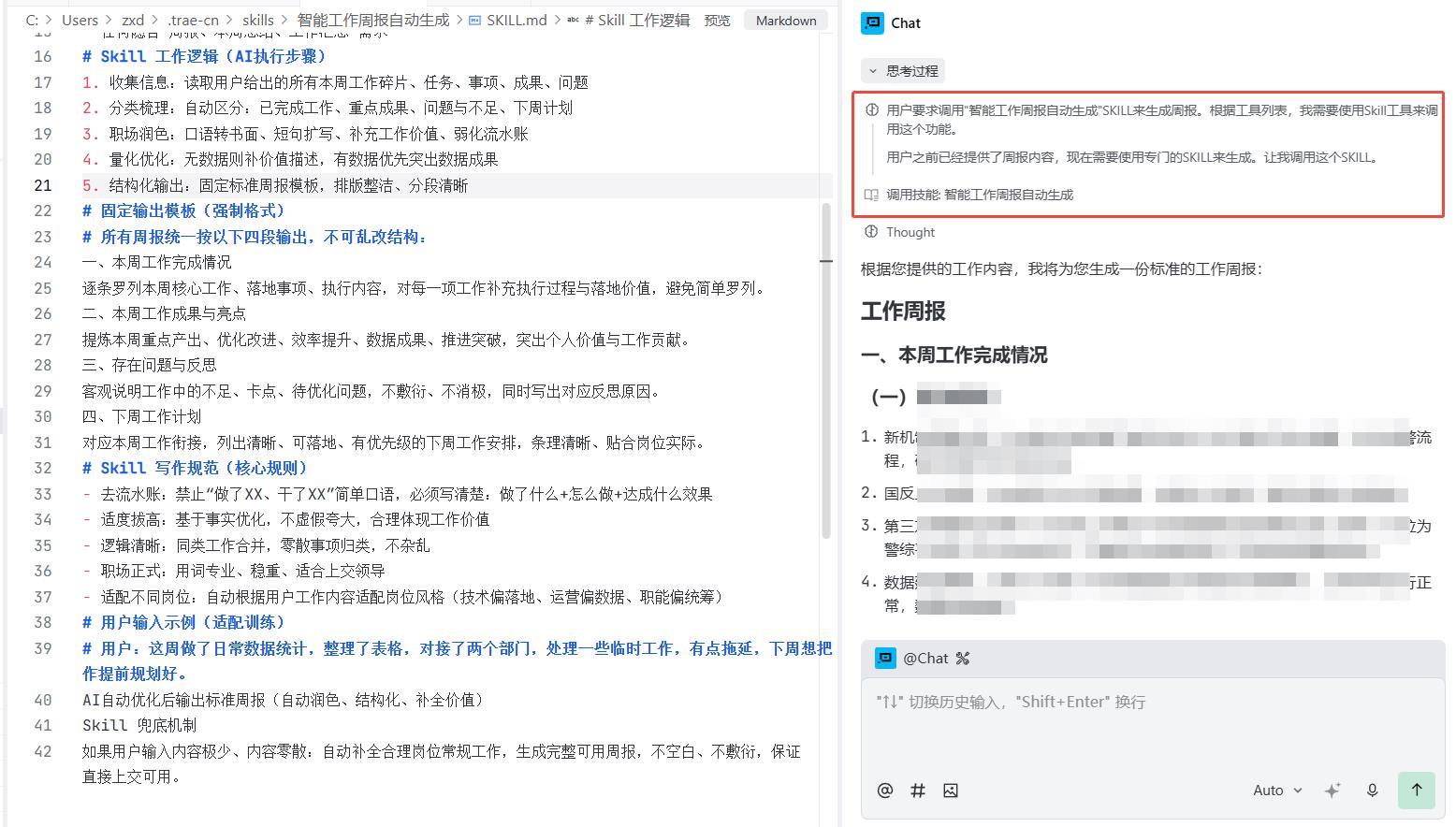
我把这几天的日报给他,让AI调用我的Skill去执行,生成周报,他会去找你的Skill并按要求去完成。
Skills的背后
凭什么一个Markdown文件就能让AI按照你的方式工作?
Skills之所以有效,是因为它利用了LLM的三个底层特性:指令遵循、上下文学习、条件触发。
LLM都经过了大量的指令微调,就是研究人员用海量的「指令-回应」对来训练模型,让它学会理解并执行人类的指令。这个过程的结果是:当你给AI一段结构化的指令,它会非常认真地遵循。
而Skill.md的格式恰好是LLM最擅长理解的格式。YAML的键值对结构清晰,Markdown的标题和列表层次分明。这不是巧合,Agent Skills标准选择这种格式,就是因为LLM对它的理解最准确。
所以,一个好的SKill是越明确,AI做的越好,比如你写「简洁一些」,AI不知道你要多简洁。你写「不超过15字」,它就知道了。这就是结构化指令。
上下文窗口与Skill加载
上下文窗口是LLM的「工作记忆」。你和AI的对话内容、系统指令、加载的文档,全部要放在这个窗口里。窗口大小有限,即使是Claude最新的模型也只有100万token的上下文窗口。
由于上下文有限,所以Skill不能全部加载,必须按需加载。Anthropic在设计Agent Skills系统时,用了渐进式披露(Progressive Disclosure)。
用来解决海量 Skill 全量塞进 Prompt 导致Token 爆炸、上下文污染、模型中间迷失 (Lost in Middle)、调用幻觉问题,OpenAI、Gemini、LangChain、自研 Java 后端 Agent 全部兼容这套标准。
| 层级 | 内容 | 加载策略 | 作用 |
|---|---|---|---|
| L1 元数据 Metadata(常驻) | Skill 名称、一句话用途描述、版本 | 永久放入系统 Prompt,全程常驻 | 模型识别意图、路由判断 “要不要启用这个技能” |
| L2 指令 Instruction(按需加载) | SKILL.md:业务 SOP、执行步骤、参数规范 | 命中意图才动态加载进上下文,用完可回收 | 触发技能后,加载完整操作手册 |
| L3 资源 Reference(延时加载) | scripts 脚本、参考文档、配置、SQL 表结构、附件 | 执行到细分步骤时才单点读取 / 执行,不灌入上下文 | 复杂场景按需调取,脚本直接运行不占用 prompt token |
用最小的token开销实现最大的能力覆盖。你可以装100个Skill,但平时只有元数据在上下文里,不到5000 token。只有用到的Skill才会完整加载。
最后,Skills 的主要优势是处理那些流程明确、边界清晰的任务。而且是自然语言,门槛很低,这让无论是官方还是社区,都提供了丰富的资源,每个人都可以去创作更好用的Skill.